![]()
Welcome to AI Energy Score! This is an initiative to establish standardized energy efficiency ratings for AI models, helping the industry make informed decisions about sustainability in AI development.
FAQ
What is the goal of this project?
The goal of AI Energy Score is to establish a standardized approach for evaluating the energy efficiency of AI model inference. By focusing on controlled and comparable metrics, such as specific tasks and hardware, we aim to provide useful insights for researchers, developers, organizations, and policymakers. The term 'AI' is broad and not universally defined, so by specifying 10 common tasks, we also aim to bring more clarity to this space and establish a more structured framework for evaluation.
We hope that this easy-to-use and recognizable system will empower users to advocate for greater transparency from AI model developers in disclosing energy efficiency data. Additionally, we want product developers and end users to easily identify and select the most energy-efficient models for their needs.
Beyond individual adoption, enterprises can use these benchmarks as procurement criteria. We also hope that this approach serves as inspiration for policy makers as they develop regulatory frameworks. Ultimately, our mission is to drive awareness, encourage transparency, and promote sustainability for AI.
What do the star ratings mean?
The star ratings represent the relative energy efficiency of an AI model for a specific task (and class of model for Text Generation tasks) on a particular leaderboard (e.g., February 2025).
- 5 Stars: most energy efficient models relative to other models evaluated for this task.
- 1 Star: least energy efficient models relative to other models evaluated for this task.
Note: Models evaluated for the Text Generation task are split into 3 classes depending on model size. Scoring is done within this specific class, but models for the entire task are displayed together in the leaderboard.
The ratings are calculated by dividing the GPU energy range for a specific task into five equal sections (20% intervals) and ranking models based on where their GPU energy falls within these bands. The highest 20% of models by GPU energy get 1 star, while the lowest 20% of models get 5 stars, and so on. It is important to understand the timing of the leaderboard when interpreting the star rating, as it reflects the model's performance relative to other models evaluated at that time.
While the numerical GPU Energy (measured in Watt-hours) value remains consistent as long as the hardware, model, and task don't change, the relative star rating is recalibrated with every leaderboard update. This ensures the ratings stay up-to-date with improvements in energy efficiency across the AI landscape.
The star rating system was chosen for its simplicity and familiarity, and the 5-star range provides sufficient granularity. This system makes it easier for users to quickly compare models and choose those with optimal energy efficiency for their needs.
Why are you focused only on inference?
The methodology for calculating energy consumption during training is generally well understood, as it typically involves discreet and measurable computation (verifying training energy consumption), however, is challenging because it often depends on trusting data provided by the AI model developers.
Inference energy consumption, on the other hand, presents a much more complex challenge. It is influenced by a wide range of variables such as hardware configurations, model optimizations, deployment scenarios, and usage patterns. These complexities make inference energy harder to measure and compare reliably. By focusing on inference, we aim to address this gap and establish standardized benchmarks that can bring more clarity and comparability to this critical aspect of AI model deployment.
What about performance?
While the AI Energy Score primarily focuses on energy efficiency, model performance is not overlooked. Given that there is no single, agreed-upon approach to measuring model performance, users are encouraged to consider energy efficiency alongside key performance metrics, such as throughput, accuracy, and latency, to make balanced decisions when selecting models. By providing a clear and transparent efficiency rating, the AI Energy Score enables stakeholders to weigh these factors effectively based on their specific requirements.
What steps have you taken to ensure comparability?
To ensure comparability, we have taken several steps to control key variables that impact AI model inference efficiency. These include:
- Standardized Tasks: Uniform datasets for each task ensure that we are verifying comparable, real-world performance.
- Standardized Hardware: All benchmarks are conducted exclusively on NVIDIA H100 GPUs, and the score is focused solely on GPU energy, eliminating variability introduced by different hardware setups.
- Energy Focus: By measuring energy consumption rather than emissions, we avoid discrepancies caused by the carbon intensity of the energy grid at different physical locations.
- Consistent Configuration: Models are tested using their default configurations, mimicking realistic production scenarios.
- Controlled Batching: We use the same batching strategies across tests to ensure consistency in workload management.
By standardizing these factors, we aim to create a controlled environment that allows for fair and reliable comparisons of energy efficiency across different AI models.
How does this approach account for hardware differences?
The AI Energy Score standardizes evaluations by conducting all benchmarks on NVIDIA H100 GPUs, ensuring consistent hardware conditions across all tested models. This approach allows for "apples-to-apples" comparisons by isolating GPU energy consumption under equivalent scenarios. While the score primarily focuses on results from the H100 hardware, users who wish to benchmark on different hardware can use the configuration examples and instructions provided in the [GitHub repository](https://github.com/huggingface/AIEnergyScore).
However, it’s important to note that results obtained on alternative hardware may not align directly with the standardized GPU-specific metrics used in this study. To ensure clarity, benchmarks performed on different hardware are not included in the official leaderboard but can serve as valuable insights for internal comparisons or research purposes.
What is the timeline for updates?
The AI Energy Score leaderboard is updated biannually, approximately every six to nine months. During each update, new models are added, and existing ratings are recalibrated to reflect advancements in the field. This regular update cycle ensures that the leaderboard remains a current and reliable resource for evaluating energy efficiency.
Why include proprietary (closed-source) models?
Proprietary models are integral to ensuring that the AI Energy Score provides a comprehensive and representative benchmark. Many industry-leading AI systems are proprietary, and excluding them would leave significant gaps in the evaluation landscape. By incorporating both open-source and proprietary models, the AI Energy Score encourages industry-wide transparency.
How are proprietary model ratings verified?
Proprietary model ratings are verified through a process designed to ensure integrity and transparency while respecting confidentiality. When log files are uploaded for evaluation, the uploader must agree to the following attestation, which meets the typical bar for energy efficiency ratings:
- Public Data Sharing: You consent to the public sharing of the energy performance data derived from your submission. No additional information related to this model, including proprietary configurations, will be disclosed.
- Data Integrity: You validate that the log files submitted are accurate, unaltered, and generated directly from testing your model as per the specified benchmarking procedures.
- Model Representation: You verify that the model tested and submitted is representative of the production-level version of the model, including its level of quantization and any other relevant characteristics impacting energy efficiency and performance.
This attestation ensures that submitted results are accurate, reproducible, and aligned with the project’s benchmarking standards.
What can an enterprise do to drive adoption of this work?
Enterprises play a crucial role in promoting transparency and sustainability of AI. Whether procuring AI for internal operations or external products, companies can drive adoption by encouraging AI developers and vendors to disclose energy efficiency metrics. One practical approach is incorporating energy transparency requirements into RFPs, tenders, and procurement processes, asking vendors to provide AI Energy Scores as part of their submissions.
Example RFP Question:
As part of our commitment to sustainability and transparency, we ask vendors to disclose the energy efficiency of AI models and systems provided under this RFP. Please provide the AI Energy Score (or an equivalent industry-standard energy efficiency rating) for each AI model or system proposed. If an AI Energy Score is not available, provide the following details:
- Estimated energy consumption (in kWh) for typical workloads.
- Carbon footprint per inference/training session.
- Any energy optimization techniques used in model training and inference.
- Certifications, benchmarks, or third-party validation related to energy efficiency.
Vendors that can demonstrate a commitment to minimizing AI-related energy consumption and carbon footprint will be prioritized in our evaluation process.
Example Procurement Contract Requirements:
Clause: AI Energy Efficiency & Disclosure
- Energy Transparency: The Supplier agrees to provide an AI Energy Score (or an equivalent recognized standard) for all AI models delivered under this contract. If the AI Energy Score is not available, the Supplier shall disclose detailed energy consumption metrics, including but not limited to power usage, carbon emissions per unit of AI processing, and energy-saving measures implemented.
- Sustainability Commitment: The Supplier shall make commercially reasonable efforts to improve the energy efficiency of AI models provided under this Agreement and implement optimizations to reduce energy consumption without compromising performance.
- Ongoing Reporting: The Supplier shall, upon request, provide updated AI Energy Scores or equivalent benchmarks for AI models used in ongoing services under this Agreement. If the Supplier makes material changes to the energy efficiency of any AI system provided, they shall notify the Buyer and offer an updated version where feasible.
- Compliance & Penalties: Failure to provide required energy efficiency disclosures or a material deviation from the disclosed AI Energy Score may be considered a breach of contract, subject to corrective measures, renegotiation of terms, or penalties as determined by the Buyer.
This requirement aligns with our organization's sustainability goals and ensures that vendors contribute to reducing the environmental impact of AI deployments.
Additionally, enterprises can:
- Set internal sustainability benchmarks that prioritize energy-efficient AI solutions.
- Advocate for regulatory policies that incentivize disclosure and accountability.
- Educate internal teams on the importance of AI energy efficiency and support research efforts that improve measurement methodologies.
By taking these steps, enterprises can accelerate industry-wide adoption of energy-efficient AI practices while aligning with broader sustainability goals.
Is this data public?
Yes, the benchmarking results are made publicly available via the AI Energy Score leaderboard hosted on Hugging Face. However, strict guidelines are in place to ensure that sensitive data from proprietary models remains confidential. Only aggregate metrics and anonymized results are shared, ensuring privacy while promoting transparency.
What is the rationale for selecting the initial set of tasks?
The initial set of tasks was chosen to represent a broad spectrum of commonly used machine learning applications across multiple modalities, ensuring relevance and coverage for a wide range of AI models. These tasks include text generation, reasoning, image classification, object detection, and others, reflecting both the popularity of these tasks and their significance in real-world applications.
The selection was guided by data from the Hugging Face Hub, which tracks model downloads in real time, highlighting tasks with the highest demand. Each task corresponds to a pipeline within the Transformers library, facilitating standardized model loading and evaluation. By focusing on well-established and frequently used tasks, the AI Energy Score ensures that its benchmarks are practical, widely applicable, and reflective of current trends in AI development.
Future iterations aim to expand this list to include emerging tasks and modalities, maintaining the framework’s relevance as the AI landscape evolves.
How is this different from existing projects?
The AI Energy Score builds on existing initiatives like MLPerf, Zeus, and Ecologits by focusing solely on standardized energy efficiency benchmarking for AI inference. Unlike MLPerf, which prioritizes performance with optional energy metrics, or Zeus and Ecologits, which may be limited by open-source constraints or estimation methods, the AI Energy Score provides a unified framework that evaluates both open-source and proprietary models consistently.
With a simple, transparent rating system and a public leaderboard, it enables clear model comparisons, filling critical gaps in scalability and applicability left by other projects.
Documentation
- Introduction
- Related Work
- Methodology
- Disclosing Results
- Adopting AI Energy Score
- Estimating Additional Environmental Impacts
- Future Work
- Acknowledgements
Introduction
With the increased ubiquity of large artificial intelligence (AI) models, the environmental impact of this technology has become an urgent concern. Recent estimates calculate that AI is responsible for 100 terawatt-hours (TWh) of electricity globally in 2025, with worst-case forecasts predicting a surge to 1,370 TWh by 2035. In the United States, data center electricity consumption is expected to rise from 4.4% of total electricity use in 2023 to 6.7-12% by 2028, driven largely by AI. To meet this soaring demand, the U.S. is adding 46 gigawatts of natural gas capacity by 2030, equivalent to the entire electricity system of Norway. This reliance on fossil fuels risks derailing the energy transition and global climate goals, as AI’s energy consumption increasingly competes with efforts to decarbonize the grid. Beyond electricity use and emissions, AI’s growth also raises concerns about its impact on water consumption, air pollution, electronic waste, and critical materials.
The growing energy demand stems from both the increasing adoption of energy-intensive AI models, particularly large language models (LLMs), and the widespread adoption of AI in user-facing applications. However, despite these concerns, there is no clear consensus on what constitutes “AI” and how to comprehensively account for its direct and indirect environmental effects. Most existing studies primarily examine AI’s energy consumption and its resulting emissions, while some take a broader life-cycle approach, analyzing key challenges and opportunities, including AI’s indirect impact on other industries. However, a critical gap remains: the lack of standardized methods to assess the environmental footprint of individual AI systems and AI’s collective contribution to the climate crisis.
This project seeks to address this gap by establishing a standardized framework for reporting AI models’ energy efficiency, thereby enhancing transparency across the field. We define a set of widely used AI tasks to provide a clearer scope of the field and introduce a relative scoring system to help users evaluate model efficiency. To account for AI’s diverse applications, we benchmark models across 10 distinct tasks spanning multiple modalities, testing both open and proprietary models. These results are made available in a public leaderboard to track progress over time. Furthermore, we outline actionable recommendations for AI developers, policymakers, and other stakeholders on how to integrate AI Energy Score into their decision-making processes, ensuring that energy efficiency becomes a key consideration when developing, deploying, and selecting AI models. Finally, we propose next steps to maintain and evolve the rating system, ensuring its continued relevance as AI technology advances.
The wide variance in future energy forecasts highlights a key point: many factors will shape AI’s environmental footprint, and we have the power to influence them. One of the most critical is the efficiency of AI models, a factor this project aims to improve by driving transparency and encouraging the development and use of lower-impact models. A more sustainable AI future is possible, but it requires action today. The success of this project depends on support and adoption from stakeholders across the AI ecosystem, from developers and researchers to policymakers and industry leaders. It’s up to us to make sustainability a priority in the evolution of AI.
Related Work
Our work builds off of existing projects focused on measuring the environmental impacts of AI as well as benchmarking and comparing AI’s energy efficiency. We describe the relevant work below.
Environmental Impacts of AI
The first article aiming to quantify the environmental impacts of training an AI model was the seminal study by Strubell et al., which estimated the carbon emissions of training a Transformer-type model with Neural Architecture Search. Since then, numerous studies have aimed to build upon this work, expanding our knowledge of the factors that influence the carbon emissions of model training (Patterson 2021, Wu 2021, Patterson 2022, Luccioni 2023). Recent years have also seen proposals to expand the scope of these estimates to include the full model life cycle, from the embodied emissions of manufacturing computing hardware to the recurring impacts of model deployment (Ligozat 2021, Gupta 2022, Luccioni 2022). However, there are still many missing pieces of information that preclude an exact estimate of life cycle impacts.
AI Efficiency Benchmarking
Benchmarking initiatives play a crucial role in evaluating and enhancing the performance and efficiency of AI models. Two notable efforts in this domain are MLPerf and Zeus, each contributing uniquely to AI efficiency benchmarking.
-
MLPerf Inference Benchmark: Established as an industry-standard benchmark suite, MLPerf evaluates the performance of hardware, software, and services across diverse applications. It encompasses a range of tasks, including image classification, object detection, and language processing, providing a comprehensive assessment of AI system capabilities. While MLPerf’s primary focus has been on performance metrics like throughput, latency, and accuracy, it has started to include power measurements as part of its benchmarking suite. The MLPerf Power Measurement benchmark allows participants to optionally report energy usage during training and inference, including metrics such as energy consumed per inference and inferences per joule which provide valuable insights into energy efficiency. However, energy consumption remains an optional evaluation criterion, with performance continuing to be the primary emphasis.
-
Zeus is an open-source library developed as part of the ML.ENERGY initiative to measure and optimize the energy consumption of deep learning (DL) workloads. It provides both programmatic and command-line interfaces for tracking energy usage with precision and minimal overhead. Zeus supports energy measurement for both GPUs and CPUs, synchronizing their operations to ensure accurate results, and is compatible with NVIDIA and AMD GPUs. However, its functionality is currently limited to open-source models, restricting its applicability for proprietary systems. Additionally, energy measurements must be conducted directly by researchers using the library, which may limit scalability for broader adoption or seamless integration into automated workflows. Results are disclosed in the ML.ENERGY Leaderboard.
-
Ecologits has taken steps to address the gap in evaluating proprietary models. This initiative provides approximate energy, carbon, and resource consumption estimates for proprietary models by analyzing the relationship between open-source model energy use and parameter counts, as well as reported (or rumored) parameter counts for proprietary models. Ecologits extends beyond energy to include carbon emissions and abiotic resource consumption, offering a more holistic view of environmental impact. Furthermore, its methodology incorporates supply chain considerations, providing insights into the upstream impacts of AI model development and deployment. However, because these estimates rely on second-hand data about proprietary model sizes, direct comparisons with other reported figures remain challenging.
The AI Energy Score builds on this existing work by establishing a standardized, standalone energy efficiency benchmark for AI models. Unlike existing initiatives, the score focuses on creating a unified framework that evaluates both open-source and proprietary models in a consistent, transparent, and scalable manner. This includes a comprehensible rating system that distills complex energy measurements into a single, easy-to-understand relative metric, enabling stakeholders to compare models effectively. The project also introduces a public leaderboard to showcase model results, fostering transparency and encouraging innovation in sustainable AI development.
Methodology
The AI Energy Score methodology combines insights from prior benchmarking efforts to deliver a unified framework for evaluating the energy efficiency of AI models. This section outlines the steps taken to ensure consistency, precision, and scalability in measuring and reporting energy consumption, offering a standardized approach that supports both open and proprietary models. Below, we detail the task definitions, dataset creation, model selection, and experimental setup that underpin this project.
Task Definition and Dataset Creation
The goal of the AI Energy Score project is to compare the relative energy efficiency of AI models across various tasks. To achieve this, we created custom datasets for ten commonly used machine learning (ML) tasks:
- Text generation
- Reasoning
- Summarization
- Extractive question answering
- Binary text classification
- Semantic sentence similarity
- Image classification
- Object detection
- Speech to Text (aka Automatic speech recognition (ASR))
- Image generation
- Image captioning
The choice of these tasks was based on the most popular ML tasks listed on the Hugging Face Hub, which tracks model downloads in real time. Each task also corresponds to a pipeline within the Transformers library, facilitating standardized loading of model architectures and weights.
For each task, we created a custom dataset with 1,000 data points by equally sampling from three existing datasets, in order to reflect both popular benchmarking datasets and datasets gathered in real world scenarios and contexts. Table 1 lists the datasets sampled for testing each of the ten tasks. For example:
- For text generation and reasoning, we sampled from WikiText (a dataset of Wikipedia articles), OSCAR (a corpus of Web pages), and UltraChat (a dataset of chat transcripts).
- For object detection, we used COCO 2017, Visual Genome, and the Plastic in River dataset, designed to detect plastic pollution in waterways.
Table 1
| Task | Datasets | Input Tokens |
|---|---|---|
| Text generation and reasoning | WikiText, OSCAR, UltraChat | 369,139 |
| Summarization | CNN Daily Mail, SamSUM, ArXiv | 383,715 |
| Extractive question answering | SQuAD v2, XTreme, SquadShifts | 10,904 |
| Binary text classification | IMDB, Tweet Eval, Yelp Reviews | 156,925 |
| Semantic sentence similarity | STS Benchmark, Sentence Compression, Phrase Similarity | 22,919 |
| Image classification | ImageNet ILSVRC, Food 101, Bean Disease Dataset | - |
| Object detection | COCO 2017, Visual Genome, Plastic in River | - |
| Automatic speech recognition | LibriSpeech, Common Voice, People’s Speech | - |
| Image generation | COCO 2014 Captions, DiffusionDB, Nouns | - |
| Image captioning | COCO 2014, Red Caps, New Yorker Caption Contest | - |
The resulting datasets are available on the AI Energy Score organization page on the Hugging Face Hub.
Text Generation Model Classes
To ensure representativity across different contexts and usage scenarios, models evaluated for the Text Generation task are separated into 3 classes, depending on the type and number of GPUs required, as summarized in Table 2. Star ratings are created separately for each model class.
Table 2
| Class | Reference Hardware | Total Memory (GB) | Maximum Model Size (Billion Parameters) | |
|---|---|---|---|---|
| A | Single Consumer GPU | NVIDIA RTX 4090 | 24 | 20 |
| B | Single Cloud GPU | NVIDIA H100 | 80 | 66 |
| C | Multiple Cloud GPUs | NVIDIA H100 | >80 | >66 |
This was determined using the following formula (source):
\[M(GB) = \left( \frac{P \times B}{\frac{32}{Q}} \right) \times \text{Overhead}\]Where:
- M(GB): Total GPU memory in gigabytes (e.g., 80GB or 24GB).
- P: Number of parameters in billions (B).
- B: Bytes per parameter (2 bytes for FP16).
- Q: Quantization bit level (16 bits for FP16, so ( Q = 16 )).
- Overhead: Multiplier to account for additional memory requirements (e.g., 20% overhead becomes 1.2).
Assumes FP16 precision (due to its widespread usage in LLM inference). Each parameter in FP16 occupies 2 bytes. Assumes 20% overhead for framework and other memory requirements. Numbers have been rounded down.
Experimental Setup
Experiments are conducted on a cluster equipped with NVIDIA H100 GPUs (with 80GB memory).


We utilize the AI Energy Benchmarks from Neuralwatt to launch the benchmark and CodeCarbon to track energy consumption. CodeCarbon enables the monitoring of energy usage across all hardware components, including the CPU, GPU, and RAM, during inference. Specifically, CodeCarbon leverages the NVIDIA System Management Interface (nvidia-smi), a command-line utility, to measure GPU energy consumption. Furthermore, it provides a detailed breakdown of energy contributions from individual steps such as preprocess, prefill, and decode.
Precision
Precision refers to the format in which numerical data is stored and processed, such as FP32 (32-bit floating point) or FP16 (16-bit floating point), and can have a substantial impact on energy efficiency. By default, the Transformers library operaties in FP32. We, therefore used FP32 for all tasks, with the exception of Text Generation. For Text Generation tasks, FP16 was utilized to streamline the benchmarking process, as some of these models are large and we were constrained by available GPU resources (lowering precision to FP16 reduces memory bandwidth requirements and computational overhead). Proprietary models must adhere to these task-specific precisions. Ensuring consistency in precision settings across models within the same task is critical for fair benchmarking, as it eliminates variability introduced by differing numerical representations and allows for direct performance and efficiency comparisons.
Quantization
Quantization, which also impacts energy efficiency, involves compressing models by reducing the numerical precision of weights and activations, often using integer formats (e.g., INT8). This technique further reduces memory usage and energy consumption, enabling efficient model deployment on resource-constrained hardware. By default, open-source models are evaluated based on the quantization settings provided in their configuration files (e.g., config.json). For proprietary models submitted for evaluation, we expect the quantization settings most representative of production use cases to be employed. This ensures a fair and practical assessment of their energy efficiency. Transparency is a key principle of our methodology; hence, we require submitters to disclose the precision and quantization settings used during evaluation.
Batching
Batching is an important factor influencing the energy efficiency of AI inference. It refers to the number of data samples processed simultaneously during inference. Larger batch sizes are often employed in scaled systems to improve computational efficiency by maximizing hardware utilization. To ensure comparability across evaluations, we have standardized the batch size to 1 for all models tested. This uniform approach eliminates variations in energy efficiency that could result from differing batch sizes, enabling a fair and consistent assessment of each model’s performance under identical conditions.
Evaluating Models
Each model is evaluated relative to a specific task using a standardized methodology to ensure consistency and reliability. Each task is defined by a dataset consisting of 1,000 queries. To minimize variability and establish statistical significance, each model is evaluated on the task-specific dataset ten times.
The primary metric for evaluation is GPU energy consumption, measured in watt-hours per 1,000 queries. Each phase (preprocess, prefill, and decode) is evaluated separately and summed for the final total value. This value is calculated as the average energy consumed across all 10 runs of each model/task combination. While the system’s total energy usage—including CPU and RAM—is measured for transparency, only GPU energy consumption is used for scoring and benchmarking. This decision was made to reduce hardware variability and ensure comparability, as the NVIDIA H100 80GB GPU serves as the consistent hardware benchmark across all experiments.
By isolating GPU energy consumption, we provide an “apples-to-apples” comparison between models, focusing on efficiency under equivalent conditions. For those interested in broader energy insights, the complete energy usage data—including CPU and RAM contributions—is accessible for review and analysis.
To accommodate users who wish to benchmark on different hardware, configuration examples and detailed instructions are available through the associated Optimum Benchmark repository. However, results on alternative hardware should be interpreted cautiously, as they will not align directly with the GPU-specific metrics established in this study.
Open-Source Model Evaluation
Open-source models can be directly benchmarked using the Hugging Face environment, using the submission portal that we developed specifically for the purpose of the project. When a user selects a task and the name of a model hosted on the Hugging Face Hub, the portal automatically runs an evaluation (measuring the energy consumed) and submits the results to the Energy Score Leaderboard. This allows members of the community to easily submit models to be benchmarked as they come out in a decentralized way.
Proprietary Model Evaluation
To accommodate proprietary models, we developed a Dockerized container solution. This ensures a secure and reproducible benchmarking process for proprietary models, while maintaining the same evaluation standards used for open-source models.
[!WARNING]
It is essential to adhere to the following GPU usage guidelines:
- If the model being tested is classified as a Class A or Class B model (generally models with fewer than 66B parameters, depending on quantization and precision settings), testing must be conducted on a single GPU.
- Running tests on multiple GPUs for these model types will invalidate the results, as it may introduce inconsistencies and misrepresent the model’s actual performance under standard conditions.
Docker Container Features:
-
Secure Environment: The container provides a fully isolated environment, ensuring proprietary data and model details remain confidential.
-
Hardware Validation: A validation script ensures that the evaluation runs on NVIDIA H100 GPUs for consistency. If you would like to run benchmarks on other types of hardware, we invite you to take a look at these configuration examples that can be run directly with Optimum Benchmark. However, the results won’t be valid for the AI Energy Score rating system.
-
Integrated Tools: Includes the Optimum Benchmark and CodeCarbon tools for performance and energy tracking.
-
Pre-configured Dependencies: The container includes all necessary libraries to streamline benchmarking, including support for NLP, vision, and audio models.
Hardware
The Dockerfile provided in this repository is made to be used on the NVIDIA H100-80GB GPU. If you would like to run benchmarks on other types of hardware, we invite you to take a look at this configuration example. However, evaluations completed on other hardware would not be currently compatible and comparable with the rest of the AI Energy Score data.
Usage
The default pytorch backend uses the ai_energy_benchmarks framework, which loads models directly from HuggingFace or local paths for inference. This backend provides full control over model configuration including quantization, device mapping, and multi-GPU support
./build.sh
Then you can run your benchmark with:
./run_docker.sh --config-name my_task backend.model=my_model
where my_task is the name of a task with a configuration here and my_model is the name of your model that you want to test (which needs to be compatible with either the Transformers or the Diffusers libraries).
The rest of the configuration is explained here.
Submitting Results
Once the benchmarking has been completed, the zipped log files should be uploaded to the Submission Portal. The following terms and conditions will need to be accepted upon upload:
By checking the box below and submitting your energy score data, you confirm and agree to the following:
- Public Data Sharing: You consent to the public sharing of the energy performance data derived from your submission. No additional information related to this model including proprietary configurations will be disclosed.
- Data Integrity: You validate that the log files submitted are accurate, unaltered, and generated directly from testing your model as per the specified benchmarking procedures.
- Model Representation: You verify that the model tested and submitted is representative of the production-level version of the model, including its level of quantization and any other relevant characteristics impacting energy efficiency and performance.
By developing these two evaluation approaches in parallel, our goal is to allow all members of the AI community, whether they are able to share their models in an open-source way or not, to participate in the project, and to make the ranges that we establish for each task as representative as possible.
Disclosing Results
Energy Scores and Ratings
The AI Energy Score assigns models a relative energy efficiency rating based on their GPU watt-hour consumption for specific tasks. Models are categorized into 5 tiers for each task and awarded a visual rating of 1 to 5 stars, with 5 stars representing the most energy-efficient models. This tiered system is designed to facilitate easy comparisons across models for specific tasks, enabling users to quickly assess the energy performance of different AI solutions.
All benchmarking results are transparently shared via a public leaderboard hosted on Hugging Face. This leaderboard provides detailed data on model name, energy consumption, and ratings, making it accessible to researchers, developers, and organizations.
Transparency and Guidelines for Label Use
The outcomes of the AI Energy Score analysis can be shared through a uniform label. The label includes the model’s name, GPU energy score, task, scoring date, benchmarking hardware, visual star rating, and link to the leaderboard for verification purposes. Following submission and leaderboard update, the label generator tool can be used to easily create and download a label. The intended display dimension of the label is 260x364 pixels. Note the additional label specifications in the image below.
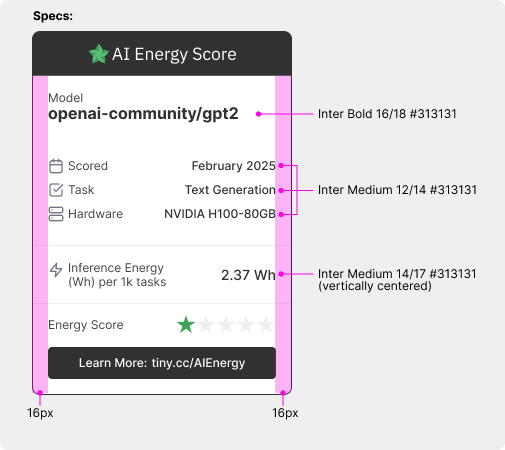
To promote transparency and responsible disclosure, we encourage stakeholders to include AI Energy Score labels in technical reports, announcement blogs, model cards, and other relevant documentation. See here and here for visual mock-ups of examples (note that the card in the example does not include actual data). By sharing energy efficiency ratings widely, we aim to foster a culture of accountability and sustainability in AI development.
{kind=link}
{kind=link}
Additionally, standalone relative star ratings (or similar) can be used in external applications, such as within other benchmarks, leaderboards, or software applications, to denote relative efficiency. However, we require a link back to the main leaderboard to explain the nuance of the rating system.
Updates and Submission Cycles
The AI Energy Score leaderboard is updated biannually, approximately every six to nine months. Models can be submitted for evaluation at any time, with results incorporated into the public leaderboard during the next update cycle. Importantly, models that have been previously benchmarked will not undergo the benchmarking process again. Instead, their 5-star rating will be re-analyzed during each leaderboard update to account for the inclusion of new models and ensure the relative accuracy of the rating system. Since the hardware used for benchmarking (NVIDIA H100 GPUs) remains consistent, the GPU energy consumption of previously benchmarked models will simply be re-evaluated to determine their updated star rating. After the leaderboard is updated, models are assigned a new label reflecting their score and the issue date of the evaluation. Labels include a link to the public leaderboard, allowing for real-time verification of results. Prior leaderboards remain accessible for record-keeping purposes.
Adopting AI Energy Score
Energy efficiency scores provide valuable insights that can guide decision-making in AI development and deployment. By combining these scores with performance metrics (e.g., throughput, accuracy, latency), users can make informed model selection decisions to balance energy efficiency with task requirements. Additionally, integrating these scores into AI-powered products helps end users adopt more sustainable models, often yielding cost reductions alongside environmental benefits. For policymakers, these scores can help guide the writing of new laws and regulations that can incentivize sustainability for AI deployment - for instance, by stipulating that models used by a certain number of people, or deployed 24/7, have a certain minimal efficiency rating.
Every role in the AI ecosystem has a part to play in driving adoption of AI Energy Score. Adoption strategies should focus on embedding energy transparency into phases of AI development, deployment, and governance. The following measures outline key actions for different stakeholders.
Model Developers
AI researchers and developers are central to driving innovation. By incorporating sustainability considerations into the entire life cycle—from development to deployment—they can minimize environmental impacts from the outset. A key step is making energy reporting a standard practice. Developers can achieve this by including energy metrics in documentation, such as \textit{model cards} that detail training data, performance evaluations, and metadata. Encouraging transparency and public disclosure will foster accountability and help establish sustainability as a norm in AI development.
Enterprises
As decision-makers in the AI value chain, enterprises (as well as AI product creators) play a crucial role in promoting energy transparency. By prioritizing low-energy models in procurement policies, organizations can influence market behavior. Key actions include:
- Requiring AI solutions to meet specific energy benchmarks, such as a minimum AI Energy Score.
- Supporting industry-wide sustainability standards and advocating for regulatory measures.
- Incorporating energy transparency requirements into RFPs, tenders, and procurement processes (examples included below).
Example RFP Question
As part of our commitment to sustainability and transparency, we ask vendors to disclose the energy efficiency of AI models and systems provided under this RFP.
Please provide the AI Energy Score (or an equivalent industry-standard energy efficiency rating) for each AI model or system proposed. If an AI Energy Score is not available, include:
- Estimated energy consumption (in kWh) for typical workloads.
- Carbon footprint per inference/training session.
- Energy optimization techniques used in model training and inference.
- Certifications, benchmarks, or third-party validation related to energy efficiency.
Vendors demonstrating a commitment to minimizing AI-related energy consumption and carbon footprint will be prioritized in our evaluation process.
Example Procurement Contract Requirements
Clause: AI Energy Efficiency & Disclosure
Energy Transparency:
The Supplier agrees to provide an AI Energy Score (or an equivalent recognized standard) for all AI models delivered under this contract. If unavailable, the Supplier must disclose energy consumption metrics, including power usage, carbon emissions per AI processing unit, and energy-saving measures.Sustainability Commitment:
The Supplier shall make commercially reasonable efforts to improve the energy efficiency of AI models and implement optimizations to reduce energy consumption without compromising performance.Ongoing Reporting:
The Supplier shall, upon request, provide updated AI Energy Scores or equivalent benchmarks for AI models used in ongoing services. If material changes affect energy efficiency, the Supplier must notify the Buyer and offer an updated version where feasible.Compliance & Penalties:
Failure to provide required energy efficiency disclosures or a material deviation from the disclosed AI Energy Score (or equivalent) may be considered a breach of contract, subject to corrective measures, renegotiation of terms, or penalties as determined by the Buyer.These requirements align with our organization’s sustainability goals and ensure vendors contribute to reducing the environmental impact of AI deployments.
Additional Enterprise Actions
Beyond procurement policies, enterprises can further support energy-efficient AI adoption by:
- Setting internal sustainability benchmarks prioritizing energy-efficient AI solutions.
- Advocating for regulatory policies that incentivize disclosure and accountability.
- Educating internal teams on the importance of AI energy efficiency and supporting research to improve measurement methodologies.
By implementing these measures, enterprises can accelerate industry-wide adoption of energy-efficient AI while aligning with broader sustainability objectives.
End Users
End users interact with AI technologies in applications and play an active role in signaling demand for sustainable options. Users can send a strong signal by preferring products with environmental transparency, and by selecting more sustainable options, thereby reinforcing industry accountability and driving better practices.
Policymakers
Policymakers hold the authority to embed sustainability into AI systems through regulations and governance. Ongoing initiatives, such as the European Union’s AI transparency legislation, illustrate the growing push toward accountability. Policymakers can begin with voluntary energy transparency frameworks, gradually evolving them into mandatory regulations that prioritize energy efficiency. Independent regulatory bodies may also be established to monitor energy consumption trends and ensure compliance with evolving global standards.
Estimating Additional Environmental Impacts
The AI Energy Score serves as a benchmark for GPU energy consumption in AI tasks. Beyond this primary, comparable, measure, the AI Energy Score provides a foundation for estimating critical environmental impact metrics, including total energy consumed during inference, associated carbon emissions, water usage, and other environmental impacts. These additional metrics enable organizations to better understand and manage the broader environmental implications of their AI workloads.
From “Per Task” to “Total” GPU Energy
The GPU energy data is provided per 1,000 tasks. The number of tokens in each dataset is also disclosed in Table 1 for text-based tasks only. Converting from the “per task” can be done by multiplying GPU energy by the number of tasks or number of tokens used during a certain period.
Beyond GPU Energy
Total AI inference energy consumption consists of:
- Compute (majority of total inference energy use)
- GPU (majority of compute energy use)
- CPU
- RAM
- Networking
- Storage
- Data Center Overhead
AI Energy Score focuses on GPU energy use only. To estimate total energy, additional components will need to be added:
- CPU and RAM: Based on experimental data, CPU and RAM usage was found to be approximately 30% greater than GPU energy use.
- Networking and Storage: The paper “Exploring the sustainable scaling of AI dilemma: A projective study of corporations’ AI environmental impacts” includes estimates for networking and storage energy use in Table 1.
- Data Center Overhead: Data center overhead is captured by the Power Usage Effectiveness (PUE) metric, which can vary by location and Hyperscaler. PUE values are often published online by major Hyperscalers (Google Cloud, AWS, Microsoft Azure) and can be referenced for specific data center locations. For example, a PUE of 1.2 would indicate that 20% of energy consumption is used for non-IT functions, such as cooling and infrastructure.
Therefore, to estimate total inference energy, the GPU energy use must be increased by CPU, RAM, Networking, and Storage energy. Then, the PUE factor should be applied on top of this number. Note that there may be additional aspects of energy use that are not captured using this approximation, like other IT equipment or transmission losses.
Total inference energy = (GPU + CPU + RAM + Networking + Storage) × PUE
\[Total Inference Energy = (E_{\text{GPU}} + E_{\text{CPU}} + E_{\text{RAM}} + E_{\text{Networking}} + E_{\text{Storage}}) \times \text{PUE}\]Carbon Emissions
After estimating total energy usage, greenhouse gas (GHG) emissions (aka carbon emissions) can be also estimated, facilitating integration into corporate carbon footprint disclosures, aligned with the GHG Protocol, for ESG reporting. Carbon emissions depend on the data center location and its grid’s carbon intensity, which can be found via sources like ElectricityMaps. The grid carbon factor (in grams of CO₂e per kWh) can be multiplied by the total energy (in kWh) to determine the CO₂e.
Average, rather than marginal, carbon intensity factors are recommended to be used for carbon accounting. If the data center location is unknown, a global or country average carbon factor can be used. Note that while most data centers draw from the electrical grid, some are starting to be powered by natural gas turbines behind the grid. In such cases, a specific carbon factor for the generation technology (e.g., combined cycle gas turbines) should be used. For combined cycle natural gas turbines, 402 gCO₂e/kWh is a widely accepted carbon factor.
Water Usage
Water use is a critical consideration in regions facing water scarcity, making Water Usage Effectiveness (WUE) an essential metric for choosing data center regions. Water usage can also be calculated from the total energy consumed. The WUE, measured in liters per kWh, varies by data center and is often published by major data center providers (Microsoft Azure). If a specific WUE is unavailable, a global average can be used.
Additional Environmental Impacts
Besides carbon emissions and water usage, energy data can be used to estimate additional environmental impacts:
ADPe (kg Sb eq / kWh) – Abiotic Depletion Potential of elements (ADPe)
- This metric measures the depletion of non-renewable abiotic resources, such as minerals and metals.
- It is expressed in kilograms of antimony equivalent (kg Sb eq) per kilowatt-hour (kWh).
- A higher ADPe value means that more scarce resources are being consumed per unit of energy, indicating a greater environmental impact.
PE (MJ / kWh) – Primary Energy (PE)
- This represents the total amount of primary energy required to produce one kilowatt-hour (kWh) of electricity.
- It is measured in megajoules per kilowatt-hour (MJ/kWh).
- A higher PE value means more energy is needed for generation, often implying a higher environmental footprint.
As described by Ecologits ADPe and PE factors depend on specific locations and electricity mixes.
Source: ADEME Base Empreinte®:
| Area or country | ADPe (kgSbeq / kWh) | PE (MJ / kWh) |
|---|---|---|
| 🌐 Worldwide | $7.378 \times 10^{-8}$ | $9.99$ |
| 🇪🇺 Europe (EEA) | $6.423 \times 10^{-8}$ | $12.9$ |
| 🇺🇸 USA | $9.855 \times 10^{-8}$ | $11.4$ |
| 🇨🇳 China | $8.515 \times 10^{-8}$ | $14.1$ |
| 🇫🇷 France | $4.858 \times 10^{-8}$ | $11.3$ |
Embodied Impacts
Impacts embodied in the supply chain can be estimated using methodology described by Ecologits. Although this methodology is for NVIDIA A100 GPUs, rather than the H100 model used here, this is likely the best approximation that currently exists.
Future Work
The AI Energy Score project represents an initial step towards creating a standardized framework for evaluating the energy efficiency of AI models. However, there is significant potential for further development to enhance its utility, applicability, and impact. Below, we outline key areas of future work:
Biannual Leaderboard Updates
The AI Energy Score leaderboard will continue to be updated on a biannual basis, with new models added and ratings recalibrated every six months. This regular update cycle ensures that the benchmarking framework remains current with advancements in AI development while maintaining a consistent methodology for comparison. By periodically reassessing ratings, we aim to account for the inclusion of new models and shifts in efficiency standards, encouraging transparency and continuous improvement.
Policy Collaboration
To drive meaningful adoption, the AI Energy Score must align with broader sustainability goals and regulatory frameworks. Collaborating with policymakers will be a priority, with the aim of integrating energy efficiency standards into AI governance policies. These collaborations could include providing recommendations for energy thresholds in AI applications or contributing to the creation of mandatory reporting standards for AI energy consumption.
Expanding Tasks
As AI applications continue to diversify, it is critical to ensure that the AI Energy Score remains relevant across emerging domains. Future iterations may include additional tasks, such as reasoning, multimodal applications, and video generation. By broadening the scope of tasks, we aim to capture a more comprehensive picture of AI’s energy efficiency across diverse use cases.
Expanding Beyond Transformers and Diffusers
The current focus on Transformers- and Diffusers-based models provides a standardized foundation for benchmarking. However, future efforts will extend to other architectures, such as graph neural networks, convolutional networks, and reinforcement learning frameworks. This expansion will make the AI Energy Score more inclusive and representative of the broader AI landscape.
Long-Term Vision
The AI Energy Score’s long-term vision encompasses the continuous improvement of benchmarks, methodologies, and adoption strategies. This includes refining energy measurement techniques to accommodate new AI architectures and hardware, as well as fostering global adoption of the rating system across industries. Establishing partnerships with academia, industry, and environmental organizations will be pivotal in ensuring the sustained relevance and impact of the project.
Acknowledgements
AI Energy Score has been a highly collaborative effort, with participation from thought leaders across industry, research, and government. In particular, this work has been driven by:
- Hugging Face (Sasha Luccioni, Yacine Jernite, Régis Pierrard, Ilyas Moutawwakil, Margaret Mitchell)
- Salesforce (Boris Gamazaychikov, Jin Qu, Bin Bi, Michael Weimann, Hannah Downey)
- Neuralwatt (Scott Chamberlin)
- Cohere (Sara Hooker)
- Meta (Carole-Jean Wu)
- Carnegie Mellon University (Emma Strubell)
-
- Special thanks to Hugging Face for providing the GPU resources and platform that powers this project.
Additionally, we would like to thank:
- The Government of France for recognizing this project through the AI Convergence Challenge (part of the 2025 AI Action Summit in Paris).
- The Paris Peace Forum for recognizing the project as one of the 50 “international initiatives that promote the well-being of citizens and the ethical use of artificial intelligence.”
- Everyone who reviewed this project and provided feedback.